Stay Ahead of the Curve
Latest AI news, expert analysis, bold opinions, and key trends — delivered to your inbox.

Latest Version
Visit PageMore About LLMWiselication
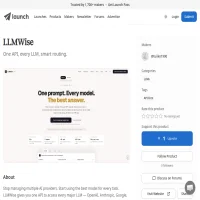
LLMWise is a multi-model LLM orchestration API that runs the same prompt across GPT, Claude, Gemini and 30+ other models in one call and provides Chat, Compare, Blend, Judge and Failover modes to compare, merge, or let AI pick the best output while streaming per-model latency, token and cost metrics; it adds production features like cost‑aware routing (auto/cost_saver), circuit‑breaker failover, BYOK, zero‑retention privacy, and Python/TypeScript SDKs so developers can experiment across models, optimize cost/latency, and add resilient, model‑agnostic AI to applications without managing multiple provider subscriptions.
Start using the best model for every task. LLMWise gives you one API to access every major LLM .
Rate the App
Add Comment & Review
User Reviews
Based on 0 reviews
No reviews added yet.
Comments will not be approved to be posted if they are SPAM, abusive, off-topic, use profanity, contain a personal attack, or promote hate of any kind.
More »



 AI Agents
AI Agents